
Oltre il Turno: L'Alba dei Modelli di Interazione
Per anni, l'interazione con l'intelligenza artificiale è stata dominata da un paradigma rigido: l'utente parla, il modello ascolta e processa, poi risponde. Un ciclo sequenziale che, sebbene funzionale, è lontano dalla fluidità della comunicazione umana. Oggi, Thinking Machines Lab rompe questo schema con l'annuncio di una nuova ricerca: i modelli di interazione (Interaction Models).
"I modelli di interazione gestiscono l'interazione in modo nativo, senza impalcature esterne. L'interattività scala insieme all'intelligenza."
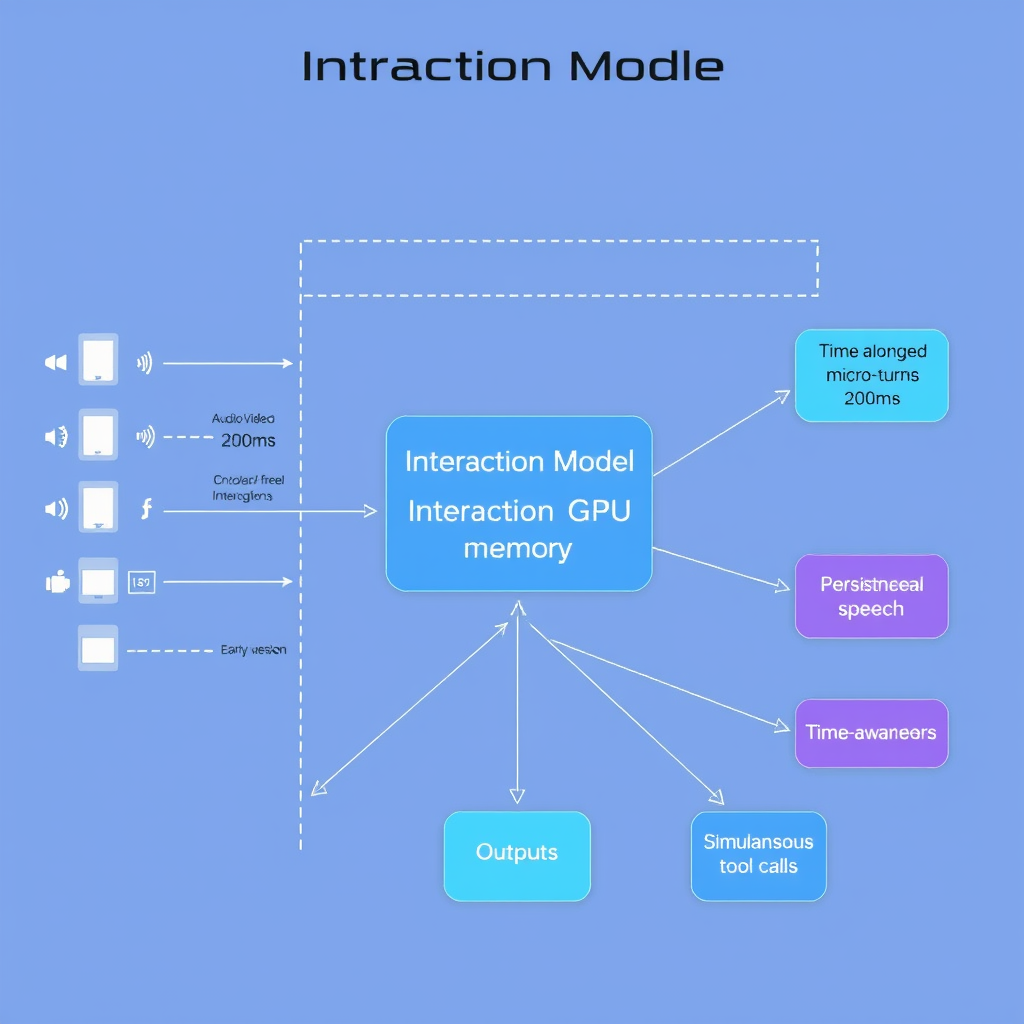
Questi modelli non sono semplici chatbot migliorati. Sono sistemi progettati per percepire, pensare e agire in tempo reale, elaborando flussi continui di audio, video e testo. L'architettura, addestrata da zero, si basa su un design a micro-turni e flussi multipli, superando i limiti di latenza e reattività che hanno finora relegato l'IA a un ruolo di assistente passivo.
Il Collo di Bottiglia della Collaborazione
L'industria dell'IA si è concentrata sull'autonomia, spinta dall'idea che gli agenti debbano lavorare da soli. Come sottolineato da un recente paper di METR (Kwa, T., West, B., Becker, J., et al., 2025), i modelli e le interfacce attuali non sono ottimizzati per il ciclo umano-nel-circuito. Persino Anthropic, nella sua scheda tecnica del modello frontier, ammette che l'uso interattivo sincrono mostra benefici meno chiari, percepito come troppo lento, mentre gli agenti autonomi riescono a far emergere meglio le capacità di coding.
Il problema è fondamentale: il lavoro reale, complesso, richiede collaborazione. Un umano che chiarisce, dà feedback, interrompe, mostra un'immagine. Le interfacce odierne, basate su turni, creano un canale stretto che spinge l'umano fuori dal loop. La comunicazione efficace, come insegnano Clark e Brennan (1991), migliora con la copresenza, la contemporaneità e la simultaneità.
I modelli commerciali attuali vivono la realtà in un singolo thread: aspettano il completamento dell'input utente e la loro percezione si congela durante la generazione. La soluzione, come suggerisce la "Bitter Lesson" di Sutton (2019), è integrare l'interattività nel modello stesso, non come un'aggiunta esterna, affinché possa scalare con l'intelligenza.
Capacità Native e un Nuovo Approccio Sistemico
Rendere l'interattività nativa al modello sblocca un ventaglio di capacità prima impossibili:
- Gestione fluida del dialogo: il modello tiene traccia del pensiero, cede la parola, si autocorregge e invita implicitamente a una risposta.
- Interruzioni verbali e visive: il modello può intervenire in base al contesto, proprio come farebbe un umano.
- Parlato simultaneo: come nella traduzione live, dove si inizia a tradurre mentre l'oratore parla ancora.
- Consapevolezza temporale: il modello sa quando è successo qualcosa e quando agire.
- Azioni simultanee: chiamate a strumenti, ricerche web o generazione di UI mentre si parla o ascolta.
L'approccio di Thinking Machines Lab è architetturale. Il sistema si basa su un modello di interazione in costante scambio bidirezionale (audio, video, testo) che delega a un modello di background per ragionamenti più profondi. Entrambi sono intelligenti, ma il modello di interazione è competitivo anche da solo.
Il Modello di Interazione in Dettaglio
Il cuore del sistema è un modello nativamente multimodale, time-aware e a flussi concorrenti:
- Micro-turni allineati temporalmente: input e output in chunk di 200ms, senza confini di turno. Questo elimina la necessità di rilevatori di attività vocale (VAD) e permette interruzioni e reazioni immediate.
- Fusione precoce senza encoder: l'audio viene processato come dMel (Bai et al., 2024), le immagini come patch 40x40 tramite hMLP (Touvron et al., 2022). L'audio decoder usa un flow head (Lipman et al., 2022). Il tutto co-addestrato da zero.
- Ottimizzazione dell'inferenza: le sessioni di streaming mantengono una sequenza persistente in memoria GPU, ottimizzata con kernel specializzati (gather+gemv per MoE) e upstreamata a SGLang.
- Allineamento Trainer-Sampler: kernel invarianti al batch con overhead <5% e attenzione Split-KV consistente per garantire determinismo.
La Frontiera dell'Intelligenza e dell'Interattività: i Benchmark
Il modello presentato, TML-Interaction-Small (un MoE da 276B parametri, 12B attivi), è il primo a combinare una forte capacità di seguire istruzioni con un'interattività nativa. I risultati dei benchmark lo dimostrano.
| Benchmark | TML-Interaction-Small | GPT-realtime-2.0 (minimal) | GPT-realtime-1.5 | Gemini-3.1-flash-live (minimal) | Qwen 3.5 OMNI-plus-realtime | GPT-realtime-2.0 (xhigh) | Gemini-3.1-flash-live (high) |
|---|---|---|---|---|---|---|---|
| FD-bench V1.5 (Media) | 77.8 | 46.8 | 48.3 | 54.3 | 39.0 | 47.8 | 45.5 |
| FD-bench V3 (Audio+Tools) Pass@1 (%) | 68.0* | 52.0 | 55.0 | 48.0 | 50.0 | 58.0 | 48.0 |
| Audio MultiChallenge APR (%) | 43.4 | 37.6 | 34.7 | 26.8 | - | 48.5 | 36.1 |
| IFEval (VoiceBench) Accuracy (%) | 82.1 | 81.7 | 68.1 | 67.6 | 80.3 | 83.2 | 82.8 |
*Con agente di background abilitato per ragionamento/chiamate a strumenti.
Il risultato chiave: TML-Interaction-Small eccelle nei benchmark che misurano l'interattività (FD-bench V1.5 e V3), dimostrando una latenza di turno di soli 0.40 secondi, la più bassa tra tutti i modelli testati. Questo si traduce in una conversazione fluida e naturale, dove il modello non è un collo di bottiglia.
Oltre ai benchmark standard, Thinking Machines Lab ha sviluppato metriche interne per misurare nuove dimensioni dell'interattività:
- TimeSpeak: il modello deve iniziare a parlare in momenti specifici con il contenuto corretto (es. promemoria per respirare).
- CueSpeak: il modello deve rispondere al momento giusto, anche mentre l'utente sta ancora parlando (es. correggere un code-switch).
- ProactiveVideoQA: il modello guarda un video e ascolta una domanda, ma deve rimanere in silenzio finché non ha la risposta, per poi intervenire proattivamente.
In questi test, nessun altro modello commerciale è in grado di performare, dimostrando che TML-Interaction-Small apre una nuova strada.
Limitazioni, Piani Futuri e un Invito alla Collaborazione
Nonostante i progressi, la strada è ancora lunga. Le limitazioni attuali includono la gestione di sessioni molto lunghe (il sistema è ottimizzato per sessioni brevi e medie) e la necessità di una connettività affidabile per il deployment. L'allineamento e la sicurezza in questo nuovo paradigma interattivo sono un'area di ricerca completamente nuova.
Thinking Machines Lab è trasparente riguardo ai piani futuri:
- Ricerca sull'allineamento: raccolta di feedback e grant per esplorare la sicurezza in contesti interattivi.
- Scalabilità: modelli pre-addestrati più grandi sono attualmente troppo lenti; il rilascio è previsto per la fine del 2026.
- Agenti di background: migliorare l'integrazione e l'intelligenza agentiva.
Per ora, il modello è disponibile in un anteprima di ricerca limitata per raccogliere feedback. Il rilascio più ampio è previsto per la fine del 2026.
"Unisciti a noi. Il futuro della collaborazione uomo-macchina non è un bot che aspetta il tuo comando, ma un partner che ti ascolta, ti guarda e interagisce con te in tempo reale."
Per feedback: interaction@thinkingmachines.ai. Per unirti al team: job-boards.greenhouse.io/thinkingmachines.


