Il dilemma del tempismo: quando chiedere chiarimenti a un agente AI
Gli agenti AI a lungo orizzonte stanno diventando sempre più comuni: sistemi capaci di eseguire flussi di lavoro complessi che coinvolgono centinaia di azioni sequenziali. Ma c'è un problema cruciale: un singolo presupposto sbagliato all'inizio dell'esecuzione può innescare errori irreversibili a cascata. Quando le istruzioni sono incomplete, l'agente deve decidere non solo se chiedere un chiarimento, ma quando farlo.
Fino ad ora, nessuno studio aveva misurato come il valore di una richiesta di chiarimento cambi nel corso dell'esecuzione. Il nuovo paper "Ask Early, Ask Late, Ask Right: When Does Clarification Timing Matter for Long-Horizon Agents?" (arXiv:2605.07937) colma questa lacuna con un'analisi sistematica e quantitativa.
Un framework per misurare il valore temporale dei chiarimenti
I ricercatori hanno sviluppato un framework a iniezione forzata: a punti controllati della traiettoria dell'agente vengono forniti chiarimenti di verità assoluta, misurando l'impatto sul successo finale. Sono state esplorate quattro dimensioni informative:
- Obiettivo (goal)
- Input
- Vincolo (constraint)
- Contesto (context)
L'esperimento ha coperto tre benchmark per agenti, quattro modelli frontier (tre per benchmark, uno usato solo su un singolo benchmark), 84 varianti di task e oltre 6.000 esecuzioni.
"Il valore di un chiarimento dipende fortemente da quale informazione manca." — dagli autori dello studio
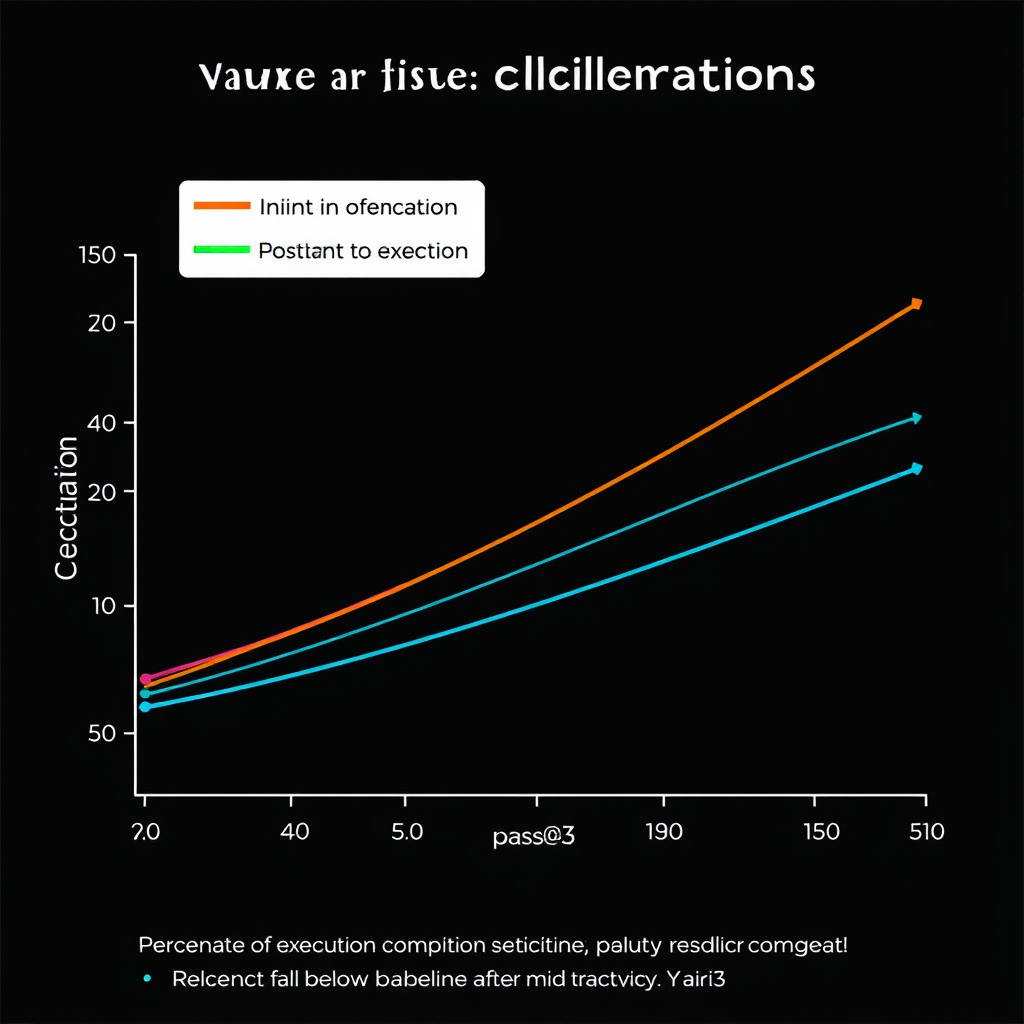
Risultati chiave: il tempismo è tutto
I dati rivelano pattern netti e sorprendenti.
- Chiarimenti sull'obiettivo: perdono quasi tutto il loro valore dopo il 10% dell'esecuzione. Il pass@3 crolla da 0,78 al livello baseline (come se non si fosse mai chiesto).
- Chiarimenti sull'input: mantengono valore fino a circa il 50% dell'esecuzione.
- Chiarimenti su vincolo e contesto: mostrano profili intermedi, ma con una regola generale: rimandare qualsiasi tipo di chiarimento oltre la metà della traiettoria degrada le prestazioni al di sotto del non chiedere mai.
Questa scoperta ha implicazioni profonde per il design di agenti autonomi: chiedere troppo tardi è peggio che non chiedere affatto.
Correlazioni tra modelli e studio delle sessioni non scriptate
Le correlazioni di Kendall tau tra modelli che condividono la stessa copertura di task sono comprese tra 0,78 e 0,87, indicando che i profili temporali sono sostanzialmente intrinseci al task, non al modello. Quando si confrontano tutti e quattro i modelli, la correlazione scende a 0,34–0,67, segno che le differenze architetturali contano, ma meno della natura del compito.
Un ulteriore studio su 300 sessioni non scriptate ha rivelato un dato allarmante: nessun modello frontier attuale chiede chiarimenti nella finestra ottimale identificata empiricamente. Le strategie osservate spaziano dal chiedere troppo (52% delle sessioni) al non chiedere mai.
"I modelli attuali non sanno quando è il momento giusto per chiedere."
Conclusioni e contributi
Il lavoro fornisce le curve di domanda empiriche che mancavano ai quadri teorici esistenti. Stabilisce target di progettazione concreti per politiche di chiarimento sensibili al tempismo.
Gli autori rilasceranno codice e dati pubblicamente, permettendo alla comunità di sviluppare agenti che sappiano non solo cosa chiedere, ma quando chiederlo.
In un panorama in cui gli agenti AI gestiscono sempre più autonomamente processi lunghi e critici, questa ricerca rappresenta un passo fondamentale verso sistemi più affidabili e meno inclini a errori a catena.