
Byte-Level AI: La Nuova Frontiera dei Modelli Linguistici
L'evoluzione dei modelli linguistici di grandi dimensioni (LLM) ha raggiunto un nuovo traguardo con l'introduzione del Fast Byte Latent Transformer (BLT). Un team di ricercatori di Stanford University, University of Washington e FAIR at Meta ha pubblicato un lavoro che promette di rivoluzionare l'efficienza computazionale, operando direttamente a livello di byte grezzi. L'articolo, disponibile su arXiv con ID 2605.08044v1, propone tre varianti innovative — BLT-Diffusion (BLT-D), BLT-Self-speculation (BLT-S) e BLT-Diffusion+Verification (BLT-DV) — che mirano a superare i colli di bottiglia dei modelli tradizionali basati su token.
"I modelli a livello di byte evitano la tokenizzazione in sottoparole, affrontando problemi come la sensibilità al rumore in input e le disparità multilingue."
Questo approccio, sebbene potente, ha storicamente sofferto di costi elevati a causa della lunghezza delle sequenze. Il nuovo studio dimostra come sia possibile ridurre il consumo di banda di memoria fino al 92%, mantenendo prestazioni competitive in compiti di traduzione e generazione di codice.
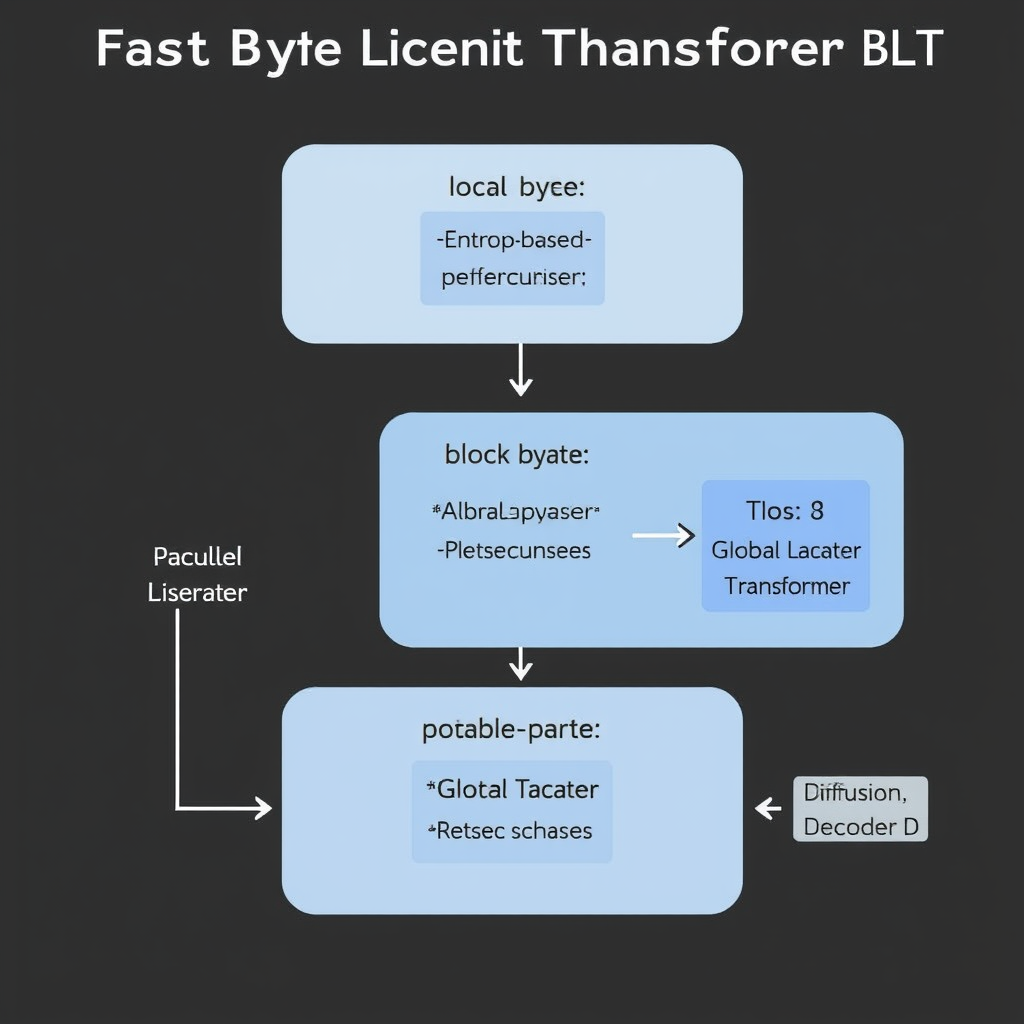
L'Architettura del BLT: Dai Byte ai Patch
Il BLT originale, sviluppato da Pagnoni et al. nel 2025, introduce un'architettura gerarchica che raggruppa i byte in patch di lunghezza variabile basati sull'entropia. In pratica, le regioni ad alta entropia (più imprevedibili) generano patch più corti, mentre le sequenze prevedibili vengono compresse in blocchi più lunghi. Questo meccanismo riduce il numero di token latenti globali da N (numero di byte) a circa N/4, ottimizzando il calcolo.
Il sistema si compone di tre elementi chiave:
- Encoder locale (ℰ): trasforma gli embedding dei byte in token latenti.
- Transformer globale (𝒢): elabora i token latenti con attenzione bidirezionale.
- Decoder locale (𝒟): ricostruisce i byte a partire dai token elaborati, utilizzando attenzione incrociata e causale.
La novità del lavoro risiede nelle modifiche apportate al decoder per supportare la generazione parallela, superando la natura autoregressiva del modello originale.
BLT-Diffusion e Self-Speculation: Le Tre Varianti
I ricercatori hanno sviluppato tre strategie complementari per accelerare l'inferenza:
-
BLT-Diffusion (BLT-D): Sostituisce la decodifica autoregressiva con un processo di diffusione discreta a livello di blocco. Durante l'addestramento, i byte vengono corrotti con una probabilità t e il modello impara a denoising parallelo. Durante l'inferenza, il decoder genera un intero blocco di byte (ad esempio, 4, 8 o 16 byte) in parallelo, riducendo drasticamente il numero di forward pass del decoder.
-
BLT-Self-speculation (BLT-S): Ispirato alla decodifica speculativa, il decoder locale "drafta" rapidamente k byte oltre il confine del patch corrente. Il modello completo (encoder + globale + decoder) verifica quindi queste bozze, accettando la sequenza fino al primo byte errato. Questo garantisce un guadagno di velocità senza perdita di accuratezza.
-
BLT-Diffusion+Verification (BLT-DV): Combina la generazione parallela della diffusione con una verifica autoregressiva finale. Il decoder diffonde un blocco di byte, poi lo verifica con un passaggio causale, recuperando la qualità persa dalla generazione puramente parallela.
| Variante | Meccanismo | Riduzione Banda (vs BLT base) |
|---|---|---|
| BLT-D-4 | Diffusione blocco 4 byte | ~50% |
| BLT-D-16 | Diffusione blocco 16 byte | 87-92% |
| BLT-DV | Diffusione + Verifica | Fino all'81% |
| BLT-S | Auto-speculazione | Fino al 77% |
Risultati Empirici e Dettagli di Addestramento
Le valutazioni sono state condotte su modelli da 1 miliardo e 3 miliardi di parametri, utilizzando il dataset BLT-1T (un sottoinsieme di Datacomp-LM). I compiti includevano:
- Traduzione: FLORES-101 (Francese-Inglese, Tedesco-Inglese) con BLEU calcolato via SentencePiece.
- Generazione di codice: HumanEval (pass@1) e MBPP (pass@1).
I risultati mostrano che BLT-D-4 eguaglia quasi le performance del BLT originale con meno del 50% delle forward pass del decoder. Per blocchi più grandi (BLT-D-16), la riduzione della banda di memoria raggiunge il 92%, sebbene con un leggero calo nelle metriche di codice. La variante BLT-DV recupera gran parte della qualità persa, rendendola ideale per applicazioni dove l'accuratezza è prioritaria.
"La stima del costo di banda di memoria è oltre il 50% inferiore rispetto al BLT base; con blocchi più grandi, si arriva a una riduzione fino al 92%."
I dettagli di addestramento rivelano un'implementazione robusta: ottimizzatore AdamW, learning rate con schedulazione coseno, e l'uso di FlashAttention per l'attenzione nei transformer. Il decoder mantiene 160 milioni di parametri sia per il modello da 1B che per quello da 3B, dimostrando l'efficienza del design.
Implicazioni e Prospettive Future
Il lavoro rappresenta un passo significativo verso modelli linguistici più efficienti e versatili. Operare a livello di byte elimina la dipendenza da tokenizer specifici per lingua, rendendo i modelli più robusti a input rumorosi e strutturati. La riduzione del consumo di banda di memoria è particolarmente rilevante per il deployment su hardware con risorse limitate, come dispositivi mobili o sistemi edge.
Tuttavia, rimangono sfide aperte. La qualità della generazione di codice con blocchi molto grandi (16 byte) mostra ancora un divario rispetto ai modelli autoregressivi puri. I ricercatori suggeriscono che l'integrazione di tecniche di verifica più sofisticate o l'addestramento con obiettivi misti potrebbe colmare questa lacuna.
In conclusione, il Fast Byte Latent Transformer non è solo un'ottimizzazione incrementale, ma un ripensamento fondamentale di come i modelli linguistici elaborano il testo. Con la combinazione di diffusione parallela e decodifica speculativa, si apre la strada a sistemi più veloci, più economici e potenzialmente più capaci di comprendere la ricchezza del linguaggio umano nella sua forma più grezza: i byte.



