
El Fin de la Conversación con Turnos: Llegan los Modelos de Interacción en Tiempo Real
Durante años, la interacción con los modelos de inteligencia artificial más avanzados se ha asemejado a un juego de tenis por correo: un jugador envía un mensaje, espera, y luego recibe una respuesta. Este modelo de turnos, aunque funcional para tareas autónomas, ha creado un cuello de botella fundamental en la colaboración humano-máquina. Los laboratorios de IA han priorizado el trabajo autónomo, pero el trabajo real y complejo—ya sea en programación, diseño o investigación—requiere un flujo constante de aclaraciones, retroalimentación y correcciones. Como señala el paper de METR (2025) sobre la capacidad de los modelos para completar tareas largas, y la propia ficha técnica de modelos frontera como Anthropic, las interfaces sincrónicas e interactivas no han mostrado beneficios claros; a menudo se perciben como demasiado lentas. La solución, sin embargo, no es abandonar la interactividad, sino redefinirla por completo.
"La comunicación mejora con la copresencia, la contemporaneidad y la simultaneidad." — Clark H. y Brennan S., "Grounding in Communication", 1991
Thinking Machines Lab ha presentado una vista previa de investigación de lo que denominan "Modelos de Interacción" (Interaction Models). Se trata de una arquitectura que integra la interactividad como una capacidad nativa del modelo, no como un añadido externo. El objetivo es emular la fluidez de una conversación humana: hablar, escuchar, ver, mostrar e interrumpir en tiempo real, sin las rígidas barreras de los sistemas actuales.
El Cuello de Botella de la Colaboración
Los interfaces actuales, basados en turnos, crean un canal de comunicación muy estrecho. Los modelos comerciales frontera experimentan la realidad en un único hilo: esperan a que el usuario termine su entrada y su percepción se congela durante el proceso de generación. Esto contrasta radicalmente con la forma en que los humanos colaboran. Mientras una persona habla, la otra asiente, interrumpe para hacer una aclaración o reacciona a un gesto. Esta sincronía es imposible con los sistemas tradicionales.
Existen ejemplos de modelos más pequeños y especializados que han explorado esta vía, como Moshi, PersonaPlex, Nemotron VoiceChat o GPT-Realtime-Translate. Sin embargo, estos suelen depender de "arneses" externos, como la detección de actividad de voz (VAD), para gestionar la interactividad. Como argumentó Richard Sutton en su influyente artículo "The Bitter Lesson" (2019), los métodos que escalan con el cómputo disponible tienden a imponerse a largo plazo. La lección aquí es clara: la interactividad no puede ser un añadido; debe ser parte intrínseca del modelo para escalar adecuadamente con la inteligencia.
La Arquitectura: Un Diálogo Constante en Dos Planos
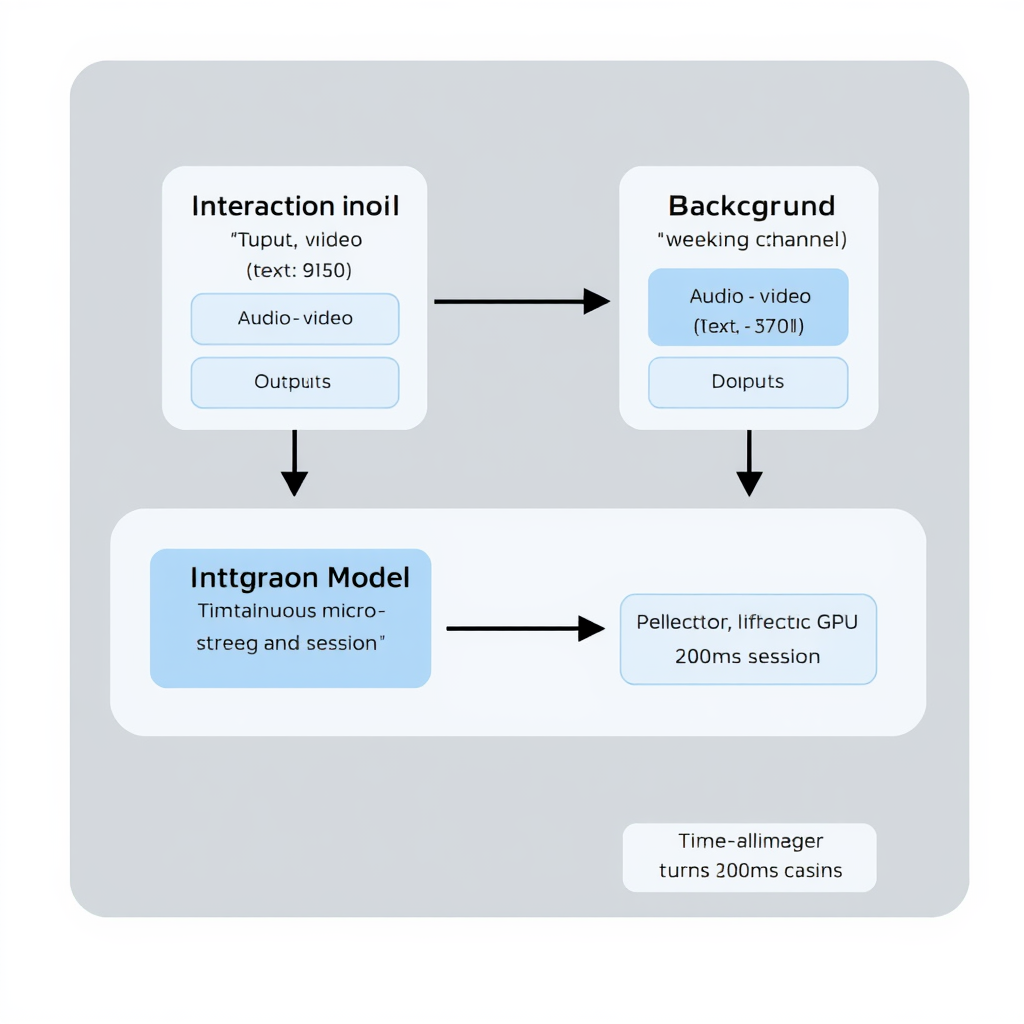
El enfoque de Thinking Machines Lab se asemeja a los sistemas utilizados en robótica o vehículos autónomos, donde la percepción y la acción son continuas. El sistema se compone de dos elementos clave:
- Modelo de Interacción: Es el que mantiene un intercambio constante y bidireccional con el usuario, procesando audio, video y texto de forma continua. Está diseñado para ser consciente del tiempo y gestionar múltiples flujos de entrada y salida simultáneamente.
- Modelo de Fondo (Background Model): Un modelo más profundo y reflexivo al que el modelo de interacción delega tareas de razonamiento complejo o llamadas a herramientas. El modelo de interacción integra los resultados de vuelta en la conversación de manera fluida.
Ambos modelos son inteligentes por sí mismos, pero el modelo de interacción es lo suficientemente capaz como para mantener una conversación competitiva por sí solo. La arquitectura se basa en trabajos previos como Qwen-omni, KAME y MoshiRAG.
Características Clave del Modelo de Interacción
El modelo de interacción (TML-Interaction-Small, un MoE de 276B parámetros con 12B activos) introduce innovaciones que lo diferencian de todo lo visto hasta ahora:
- Micro-turnos alineados en el tiempo: Procesa la entrada y genera la salida en fragmentos de 200ms. No existen límites de turno. Esto permite interrupciones, reacciones a estímulos visuales mientras se habla, o hablar mientras se escucha, eliminando la necesidad de arneses como el VAD.
- Fusión temprana sin codificador: El audio se procesa como dMel, las imágenes como parches de 40x40 píxeles, y el decodificador de audio utiliza un flujo (flow head). Todo se entrena desde cero de manera conjunta.
- Optimización de inferencia: Las sesiones de streaming mantienen una secuencia persistente en la memoria de la GPU, lo que permite una comunicación fluida y sin reinicios.
Resultados: La Frontera de la Inteligencia y la Interactividad
Los benchmarks presentados demuestran que el modelo no solo es interactivo, sino también extremadamente inteligente. La tabla siguiente muestra una comparativa con los modelos de interacción en tiempo real más avanzados del mercado.
| Benchmark | TML-Interaction-Small | GPT-realtime-2.0 (minimal) | Gemini-3.1-flash-live (minimal) | Qwen 3.5 OMNI-plus-realtime |
|---|---|---|---|---|
| FD-bench V1.5 (Audio) | 77.8 | 46.8 | 54.3 | 39.0 |
| Audio MultiChallenge APR (%) | 43.4 | 37.6 | 26.8 | - |
| IFEval (VoiceBench) Accuracy (%) | 82.1 | 81.7 | 67.6 | 80.3 |
| IFEval Accuracy (%) - Texto | 89.7 | 89.6 | 85.8 | 83.4 |
Nota: Los valores en negrita indican el mejor resultado por fila. El modelo TML-Interaction-Small muestra un rendimiento líder en métricas de interactividad (FD-bench) y competitivo en benchmarks de inteligencia como IFEval.
El modelo no solo iguala, sino que supera a la competencia en métricas clave de interactividad como el FD-bench, que evalúa escenarios como interrupciones, habla simultánea y reacciones a sonidos de fondo. Además, en benchmarks de inteligencia y seguimiento de instrucciones como IFEval, se sitúa a la par de los modelos más grandes, demostrando que la interactividad no sacrifica la capacidad de razonamiento.
Nuevas Dimensiones de la Interactividad
Thinking Machines Lab ha desarrollado benchmarks internos que exploran capacidades que ningún otro modelo comercial puede realizar actualmente:
- TimeSpeak: El modelo debe iniciar una conversación en un momento exacto (por ejemplo, "recuerda respirar hondo en 10 segundos"), evaluando tanto la precisión semántica como temporal.
- CueSpeak: El modelo debe intervenir en el momento justo mientras el usuario está hablando, por ejemplo, para corregir un error de código o traducción.
- Proactividad Visual (RepCount-A, ProactiveVideoQA, Charades): El modelo recibe un video en streaming y una instrucción de audio, y debe responder o actuar (contar repeticiones, responder una pregunta, decir 'start'/'stop') en el momento exacto en que ocurre un evento visual.
Estos benchmarks abren la puerta a aplicaciones completamente nuevas, desde asistentes de fitness que cuentan repeticiones en tiempo real hasta herramientas de edición de video que responden a comandos hablados mientras se visualiza el contenido.
Limitaciones y Hoja de Ruta
A pesar de los avances, el modelo presenta limitaciones. Las sesiones largas siguen siendo un desafío debido a la acumulación de contexto, aunque el sistema de streaming maneja bien sesiones cortas y medianas. El despliegue requiere una conectividad de red fiable y es sensible a retrasos. La seguridad y la alineación en este nuevo paradigma de interacción continua son áreas de investigación activa, para las cuales la compañía está recopilando feedback y abriendo convocatorias de becas.
El lanzamiento público está previsto para finales de 2026, con una vista previa de investigación limitada que ya está disponible para obtener retroalimentación. Thinking Machines Lab invita a la comunidad a unirse y contribuir a definir el futuro de la colaboración humano-máquina.